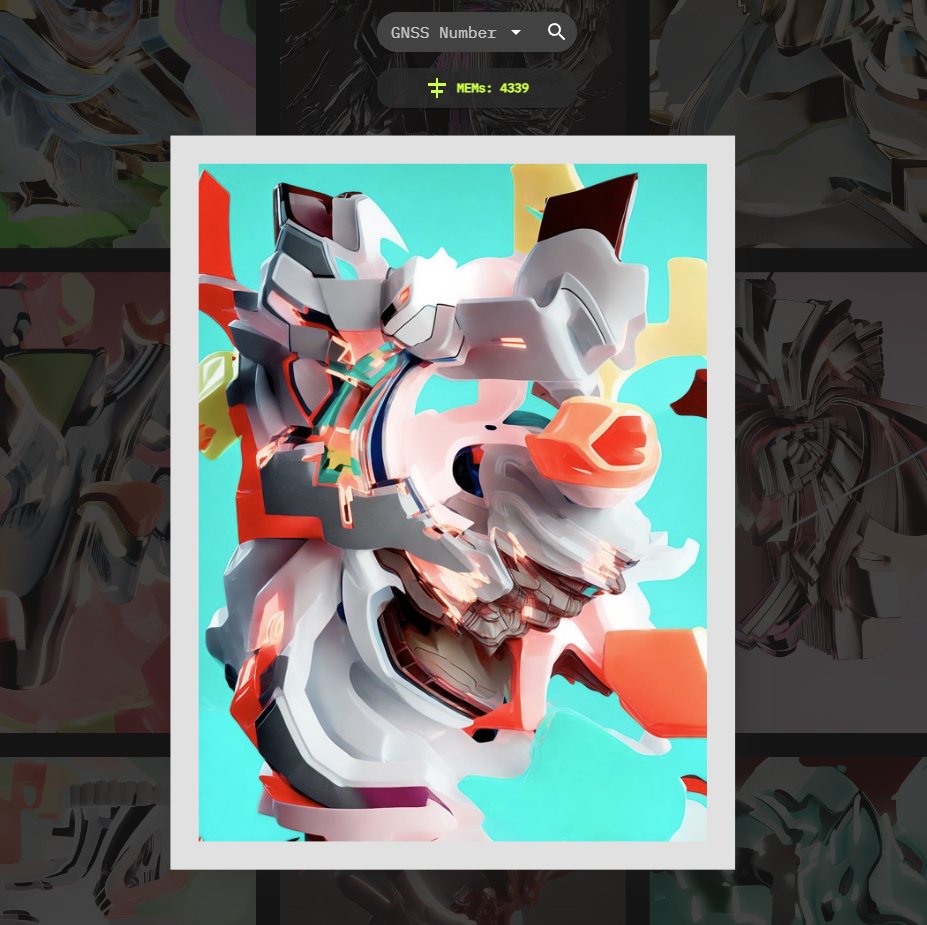
GNSS — Generative Nature Synthetic Species — is a generative art ecosystem: a collection of synthetic species, each one unique, each one carrying in its metadata the seed of its own future variations.
Underneath the art sits the part that matters most in hindsight: a fine-tuned Stable Diffusion model running in production on AWS SageMaker in 2023 — a custom inference pipeline, a serverless API around it, and a live audience feeding it prompts. Built before "deploy a foundation model" was a console checkbox.
Machine Embedded Memories
Each GNSS piece embeds structured metadata. The MEM system — Machine Embedded Memories — treats that metadata as conditioning input: traits become embeddings, embeddings condition new Stable Diffusion generations, and every output becomes a new node in the lineage. The collection grows out of itself, one generation feeding the next.
Fine-tuning the model
Model work lived in Python and Jupyter, with training and evaluation runs on GPU notebooks. Starting from open Stable Diffusion checkpoints via HuggingFace, the model was fine-tuned with proprietary embeddings derived from the collection's trait vocabulary — so the species' visual DNA was encoded in the model itself, not bolted on through prompt engineering. Model artifacts were versioned and shipped to S3 as the handoff point between research and serving.
Serving on SageMaker
The serving layer is where most generative art projects of that era stayed a notebook. GNSS didn't:
- Custom inference script + model artifacts packaged and uploaded to S3
- SageMaker real-time endpoint on g5.12xlarge, autoscaling up to ×10 during mint storms — generation lands in 6–12s; cold starts (~20s on the first mint of the day) get masked by replaying the previous MEM emerging
- Deterministic by design — token metadata → seed → prompt scaffold; the same input paints the same MEM, every time, which is what lets the collection live on-chain without ever freezing its art
- Lambda + API Gateway in front — the endpoint never exposed directly; the REST API handles request shaping, queuing and auth before anything touches the GPU
- Secrets Manager for credentials, GitHub CI/CD — model and infra versioned together
The ecosystem around the model
A model in production is mostly the system around it. The full request path: CloudFlare DNS → CloudFront → API Gateway → Lambda → SageMaker, with four S3 origins (www, ai, tree, embed) serving the front ends and generated output. Firebase AppCheck gates client calls, MongoDB holds the species metadata, and the collection itself settles on Ethereum.
01 request path
every generationclientmem.mgxs.cocloudflarednscloudfrontcdn edgeapi gatewayrestlambdarest api02 training loop
research → artifactjupyterfine-tuningembeddingsproprietary traitsmodel.tar.gzinference scripts3artifact store03 chain & marketplacesmint → list → trade
04 state & trustaround the model
- mongodbspecies metadata
- firebase appcheckclient auth
- secrets managercredentials
- s3 origins ×4www · ai · tree · embed
- githubci/cd
Chain & marketplaces
The species don't stop at the API — the collection settles on Ethereum as ERC-721, with minting gated through Firebase AppCheck and Functions. The deliberate design choice is the metadata: each token's tokenURI points back at the ecosystem's own API (api.mgxs.co, backed by MongoDB) instead of a frozen JSON dump, so traits stay alive, versioned and queryable — the same records that condition the next generation of MEMs.
OpenSea and Rarible pick the collection up from there. Listings, secondary trades and royalties ride the marketplaces, but every image and trait they display is served by the same CloudFront + S3 + MongoDB stack that generates new species. The marketplaces are consumers of the system, not its home.
Live at NFC Lisbon '23
The pipeline's real stress test was a live installation in Lisbon: attendees fed the system directly and watched their input become new species, generated on the spot. End-to-end inference — input, embedding, generation, delivery — performing in front of a crowd.
Tree of MEMs
Because every MEM is conditioned on its ancestors' metadata, the lineage is traceable. The Tree of MEMs visualises the collection as exactly that — a tree, where you can dig into the roots of any individual piece and follow the branches its memories produced.